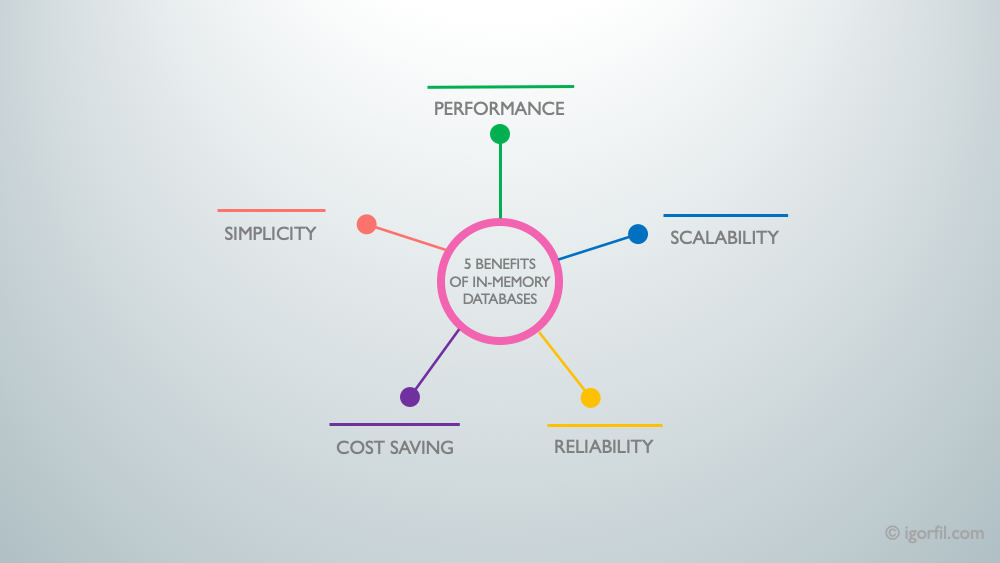
5 Benefits Of In-Memory Databases
In-memory data stores like Redis are becoming increasingly important components of modern distributed systems. Managed solutions like AWS ElastiCache are the cornerstones of the Cloud Computing. Let’s explore what are their benefits and what makes them so popular.
What is it
In-memory data stores are databases. Just like any other database, they store data and return it on requests. But there is one fundamental difference. The purpose of traditional database is to store data for a long time. In-memory databases are the opposite, their goal is to store data temporary, like cache. Traditional databases store data on hard drive (HDD or SSD). In contrast, in-memory databases keep all data set in computer’s memory - RAM. Performance is the killer feature of in-memory data stores. They do not need to perform disk read/write operations to return data. They just read it from RAM which is blazingly fast.
5 benefits of in-memory data stores
1. Improved Performance
When you want to retrieve data from a traditional database, most operations would require to read from a disk. No matter if it is HDD or SSD disk, it is much slower than reading data from memory. In-memory databases don’t need to read from disk, they can therefore perform much more operations using the same amount of time. Redis can perform millions read/write operations per second, each taking less than a millisecond.
How can you use it in the real world? One of the popular usage patterns is to take load off the main database. In-memory databases can be used as efficient cache. Imagine you are running a news website. You store articles in a relational database and that your backend serves to viewers. You have a section that shows most popular stories. On every user request, the backend must go to the database and run a query that would select articles and sort them by popularity. On a small website with just a handful of articles it would work fine. But when stories count go into tens of thousands, this query would need to process more and more data thus getting slower and slower. User will see page load slower and slower.
But notice that the query for most popular articles will produce the same result over and over again. If result is the same every time - why recalculate it? You can just re-use the result that you get from a previous calculation. You can cache this result in in-memory database. You will be able to retrieve this data very fast. And you can always recalculate it when needed - just to refresh it periodically or if data is lost.
2. Improved Scalability
A system will be as fast (or as slow) at its slowest part. Pretty often this slowest part will be a database. You can have a lightning-fast backend application, but it will be able to serve user’s request only as fast as the database can produce data. It becomes even more evident in a system that experiences high load and needs to serve high volumes of traffic.
There is always a limit on database throughput. At a point when traditional persistent database will be struggling to keep up with requests, in-memory database will perform just fine. But when even that is not enough, in-memory data stores can be scaled up much easier to serve even more traffic (with replication and partitioning).
As your traffic grows, it gets harder and harder for the main database to keep up and serve all requests in time. Imagine that some important event happens that draws people to the news website that you run. Thousands of people will want to go to your website to read a story at the same time. When your traffic spikes, so will the load to your database. At a certain point it will overwhelm the database, there will be more requests that it can handle. It will start dropping requests or take very long time to reply. It may render your entire system inoperable.
Adding in-memory cache will move that breaking point much much further. Not only that, but it will be more flexible - you will be able to move it up and down as you need (by increasing or decreasing size of the cache cluster). As a result, the system will be able to handle much higher throughput than the slowest part of your system (database) allows and be more responsive to changes in demand (traffic).
3. Improved Reliability
In-memory data store can improve reliability of your system. It can protect database from surges in traffic that can bring the entire system down.
In the previous example of surge in traffic, if left alone, persistent database can be just overwhelmed with traffic and will no longer be able to serve any requests. But with help from in-memory cache, you can serve much more requests and do it safer, spikes in traffic will have less chance to bring the system down.
Additionally, database no longer becomes a single point of failure. Your database can go completely offline but your system can keep working - it will read all the data that it needs from in-memory cache. It may not even notice that database went off-line for some time!
4. Cost Saving
Databases are expensive. They are expensive to maintain and scale. If you want to serve more requests, you need a bigger database server or more database servers. But they come with a hefty price tag. In-memory cache can help you to reduce that cost. Small in-memory data store can dramatically reduce load to the main database. As a result, you can run smaller database and serve more traffic that the database could do alone. Combined cost of running a traditional database and in-memory cache would be less than running a bigger database of the same performance.
Additionally, it is hard to guess correctly how big your database server needs to be. You can opt for smaller database to serve low traffic, but when the traffic grows, it will no longer be able to function. On the other hand, if you provision a database that is too big, it will be running at idle performance most of the time, wasting money. In-memory cache allows to run smaller database and make system more flexible and more adaptable to variations in load.
What is also important, in-memory database can improve overall reliability and availability of the system. As a result, system will have less downtime. Downtime is expensive - when the system is down it does not generate any revenue. It also takes a lot of expensive programmer’s time to diagnose and fix it.
5. Simplicity and ease of use
In-memory data stores support multiple data structures for any need. Unlike simplistic data structures that traditional databases can store (strings, ints, floats), in-memory databases can store much more complex data. In case of Redis, the most popular of the kind, you can store strings, lists, hashes, sets, geospatial data and many more. But it is not only about data structures - access patterns that these solutions offer are designed specifically for use patterns that you might need. You can query data by key, perform range-based queries, automatic eviction (when old data is deleted automatically), etc.
This allows you to simplify your application code when using Redis - if you want to store a hash map, you just store it as is - you don’t need to convert it to any other data structure or perform serialization. You can write and maintain less code, getting same or even grater result. It gives you bigger bang for the buck.
Takeaway
Redis has been voted as the most popular database technology for many years in a row in Stack Overflow survey. In-memory databases are very handy tools that are easy to use. Adding one to your system can provide many benefits. Cloud service providers, such as Amazon Web Services, offer managed solutions for in-memory databaes, for example ElastiCache. These services take heavy lifting off your shoulders, such as capacity management, backups, failover and many more, allowing you to focus on important parts of your system. It makes them even more accessible and attractive.
Do you have any stories of how in-memory data stores improved your systems? Please share it in comments below!

See Also

Understanding Redis replication in AWS ElastiCache
How to get more done with less time using Pomodoro Technique
Should You Build In The Cloud?
How can you benefit from using cloud computing
